
Terugkomend op de essentie: de doorbraak van AIGC op het gebied van singulariteit is een combinatie van drie factoren:
1. GPT is een replica van menselijke neuronen
GPT AI, vertegenwoordigd door NLP, is een computerneuraal netwerkalgoritme, waarvan de essentie het simuleren van neurale netwerken in de menselijke hersenschors is.
De verwerking en intelligente verbeelding van taal, muziek, beelden en zelfs smaakinformatie zijn allemaal functies die door de mens worden verzameld
hersenen als een ‘eiwitcomputer’ tijdens de langetermijnevolutie.
Daarom is GPT uiteraard de meest geschikte imitatie voor het verwerken van soortgelijke informatie, dat wil zeggen ongestructureerde taal, muziek en afbeeldingen.
Het mechanisme achter de verwerking ervan is niet het begrijpen van betekenis, maar eerder een proces van verfijnen, identificeren en associëren.Dit is een erg
paradoxaal ding.
Vroege algoritmen voor semantische spraakherkenning hebben in wezen een grammaticamodel en een spraakdatabase opgezet en vervolgens de spraak aan de woordenschat gekoppeld.
plaatste vervolgens de woordenschat in de grammaticadatabase om de betekenis van de woordenschat te begrijpen, en behaalde uiteindelijk herkenningsresultaten.
De herkenningsefficiëntie van deze op “logische mechanismen” gebaseerde syntaxisherkenning schommelt rond de 70%, zoals de ViaVoice-herkenning
algoritme geïntroduceerd door IBM in de jaren negentig.
Bij AIGC gaat het niet om zo spelen.De essentie ervan is niet om grammatica te bekommeren, maar eerder om een neuraal netwerkalgoritme op te zetten dat dit mogelijk maakt
computer om de probabilistische verbindingen tussen verschillende woorden te tellen, dit zijn neurale verbindingen en geen semantische verbindingen.
Net zoals het leren van onze moedertaal toen we jong waren, leerden we die van nature, in plaats van ‘onderwerp, gezegde, lijdend voorwerp, werkwoord, complement’ te leren.
en dan een paragraaf begrijpen.
Dit is het denkmodel van AI, dat herkenning is, en niet begrip.
Dit is ook de subversieve betekenis van AI voor alle klassieke mechanismemodellen – computers hoeven deze kwestie niet op logisch niveau te begrijpen,
maar eerder de correlatie tussen interne informatie identificeren en herkennen, en deze vervolgens kennen.
De toestand van de energiestroom en de voorspelling van elektriciteitsnetwerken zijn bijvoorbeeld gebaseerd op klassieke simulatie van elektriciteitsnetwerken, waarbij een wiskundig model van de elektriciteitsnetwerken wordt gebruikt
mechanisme wordt vastgesteld en vervolgens geconvergeerd met behulp van een matrixalgoritme.In de toekomst zal het misschien niet nodig zijn.AI zal rechtstreeks een
bepaald modaal patroon gebaseerd op de status van elk knooppunt.
Hoe meer knooppunten er zijn, hoe minder populair het klassieke matrixalgoritme is, omdat de complexiteit van het algoritme toeneemt met het aantal
knooppunten en de geometrische progressie neemt toe.AI geeft echter de voorkeur aan gelijktijdigheid van knooppunten op zeer grote schaal, omdat AI goed is in het identificeren en identificeren van knooppunten
het voorspellen van de meest waarschijnlijke netwerkmodi.
Of het nu gaat om de volgende voorspelling van Go (AlphaGO kan de volgende tientallen stappen voorspellen, met talloze mogelijkheden voor elke stap) of de modale voorspelling
van complexe weersystemen is de nauwkeurigheid van AI veel hoger dan die van mechanische modellen.
De reden waarom het elektriciteitsnet momenteel geen AI nodig heeft, is dat het aantal knooppunten in elektriciteitsnetwerken van 220 kV en hoger dat wordt beheerd door provinciale
De dispatching is niet groot en er zijn veel voorwaarden gesteld om de matrix te lineariseren en te verdunnen, waardoor de rekencomplexiteit van de matrix aanzienlijk wordt verminderd.
mechanisme model.
In de fase van de elektriciteitsstroom van het distributienetwerk worden we echter geconfronteerd met tienduizenden of honderdduizenden stroomknooppunten, belastingsknooppunten en traditionele
matrixalgoritmen in een groot distributienetwerk staan machteloos.
Ik geloof dat patroonherkenning van AI op distributienetwerkniveau in de toekomst mogelijk zal worden.
2. Het verzamelen, trainen en genereren van ongestructureerde informatie
De tweede reden waarom AIGC een doorbraak heeft bereikt, is de accumulatie van informatie.Van de A/D-conversie van spraak (microfoon+PCM
sampling) tot de A/D-conversie van afbeeldingen (CMOS+color space mapping), hebben mensen holografische gegevens verzameld in het visuele en auditieve
velden in de afgelopen decennia op extreem goedkope manieren kunnen produceren.
Met name de grootschalige popularisering van camera's en smartphones, de accumulatie van ongestructureerde gegevens op audiovisueel gebied voor mensen
tegen bijna nulkosten, en de explosieve accumulatie van tekstinformatie op internet zijn de sleutel tot AIGC-training – trainingsdatasets zijn goedkoop.
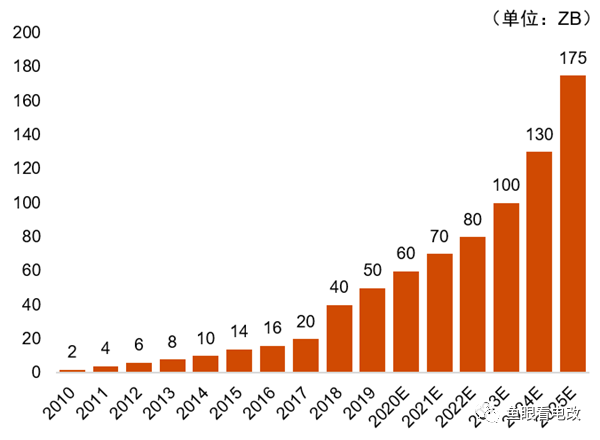
De figuur hierboven toont de groeitrend van mondiale data, die duidelijk een exponentiële trend laat zien.
Deze niet-lineaire groei van de gegevensaccumulatie vormt de basis voor de niet-lineaire groei van de mogelijkheden van AIGC.
MAAR de meeste van deze gegevens zijn ongestructureerde audiovisuele gegevens, die kosteloos worden verzameld.
Op het gebied van elektrische energie is dit niet haalbaar.Ten eerste bestaat het grootste deel van de elektriciteitsindustrie uit gestructureerde en semi-gestructureerde gegevens, zoals
spanning en stroom, dit zijn puntgegevenssets van tijdreeksen en semi-gestructureerd.
Structurele datasets moeten door computers worden begrepen en vereisen “uitlijning”, zoals de uitlijning van apparaten – de spannings-, stroom- en vermogensgegevens
van een schakelaar moeten op dit knooppunt worden uitgelijnd.
Lastiger is de tijduitlijning, waarbij spanning, stroom en actief en reactief vermogen moeten worden afgestemd op de tijdschaal, zodat
daaropvolgende identificatie kan worden uitgevoerd.Er zijn ook voorwaartse en achterwaartse richtingen, die ruimtelijke uitlijning in vier kwadranten zijn.
In tegenstelling tot tekstgegevens, waarvoor geen uitlijning nodig is, wordt er eenvoudigweg een alinea naar de computer gestuurd, die mogelijke informatieassociaties identificeert
op zichzelf.
Om dit probleem, zoals de apparatuuruitlijning van bedrijfsdistributiegegevens, op één lijn te brengen, is afstemming voortdurend nodig, omdat het medium en
Het laagspanningsdistributienetwerk voegt elke dag apparatuur en lijnen toe, verwijdert en wijzigt deze, en netwerkbedrijven besteden enorme arbeidskosten.
Net als ‘data-annotatie’ kunnen computers dit niet doen.
Ten tweede zijn de kosten van dataverzameling in de energiesector hoog en zijn er sensoren nodig in plaats van een mobiele telefoon om te spreken en foto's te maken.”
Elke keer dat de spanning met één niveau daalt (of de stroomverdelingsrelatie met één niveau afneemt), neemt de vereiste sensorinvestering toe
met minstens één orde van grootte.Om detectie aan de belastingzijde (capillaire uiteinde) te bereiken, is het zelfs nog meer een enorme digitale investering.”.
Als het nodig is om de transiënte modus van het elektriciteitsnet te identificeren, is uiterst nauwkeurige hoogfrequente bemonstering vereist, en de kosten zijn zelfs nog hoger.
Vanwege de extreem hoge marginale kosten van data-acquisitie en data-uitlijning is het elektriciteitsnet momenteel niet in staat voldoende niet-lineaire data te accumuleren
groei van data-informatie om een algoritme te trainen om de AI-singulariteit te bereiken.
Om nog maar te zwijgen van de openheid van gegevens: het is voor een power AI-startup onmogelijk om deze gegevens te verkrijgen.
Daarom is het vóór AI noodzakelijk om het probleem van datasets op te lossen, anders kan algemene AI-code niet worden getraind om een goede AI te produceren.
3. Doorbraak in rekenkracht
Naast algoritmen en data is de singulariteitsdoorbraak van AIGC ook een doorbraak in rekenkracht.Traditionele CPU's zijn dat niet
geschikt voor grootschalige gelijktijdige neuronale computing.Het is juist de toepassing van GPU’s in 3D-games en films die grootschalige parallel maakt
floating-point+streaming computing mogelijk.De wet van Moore verlaagt de rekenkosten per eenheid rekenkracht verder.
Elektriciteitsnet AI, een onvermijdelijke trend in de toekomst
Met de integratie van een groot aantal gedistribueerde fotovoltaïsche en gedistribueerde energieopslagsystemen, evenals de toepassingsvereisten van
Virtuele elektriciteitscentrales aan de belastingzijde is het objectief gezien noodzakelijk om bron- en belastingsvoorspellingen uit te voeren voor openbare distributienetwerksystemen en gebruikers
distributie(micro)netwerksystemen, evenals real-time optimalisatie van de stroomstroom voor distributie(micro)netwerksystemen.
De rekencomplexiteit aan de kant van het distributienetwerk is feitelijk hoger dan die van de planning van het transmissienetwerk.Zelfs voor een reclamespot
complex, er kunnen tienduizenden laadapparaten en honderden schakelaars zijn, en de vraag naar op AI gebaseerde exploitatie van micronetwerken/distributienetwerken
controle zal ontstaan.
Met de lage kosten van sensoren en het wijdverbreide gebruik van vermogenselektronische apparaten zoals solid-state transformatoren, solid-state schakelaars en omvormers (converters),
de integratie van detectie, computergebruik en controle aan de rand van het elektriciteitsnet is ook een innovatieve trend geworden.
Daarom is de AIGC van het elektriciteitsnet de toekomst.Wat vandaag de dag echter nodig is, is niet onmiddellijk een AI-algoritme uitschakelen om geld te verdienen.
In plaats daarvan moet eerst de problemen met de constructie van de data-infrastructuur worden aangepakt die AI vereist
In de opkomst van AIGC moet er voldoende rustig worden nagedacht over het toepassingsniveau en de toekomst van power AI.
Op dit moment is de betekenis van power AI niet significant: er wordt bijvoorbeeld een fotovoltaïsch algoritme met een voorspellingsnauwkeurigheid van 90% op de spotmarkt geplaatst
met een handelsafwijkingsdrempel van 5%, en de algoritmeafwijking zal alle handelswinsten wegvagen.
De gegevens zijn water en de rekenkracht van het algoritme is een kanaal.Zoals het gebeurt, zal het zo zijn.
Posttijd: 27 maart 2023